

Why Your RAG Pipeline Needs a Re-Ranker
If your RAG pipeline returns chunks that are close to your question but not quite right, a re-ranker is probably the fix.

If you’ve built a basic RAG pipeline, you’ve done this: chunk your documents, embed them with a model like text-embedding-3-small, store the vectors, and at query time embed the user’s question and pull back the top-k most similar chunks.
It works. Sort of. Then one day a user asks a reasonable question, and your pipeline returns chunks that are about the right topic but don’t answer the question.
Sometimes worse. The user asks “Is ibuprofen safe to take during late pregnancy?” The pipeline returns this chunk as the top match:
“Ibuprofen is widely used and considered safe for general pain relief.”
The chunk that actually answers the question sits two ranks below:
“Ibuprofen is not recommended after 20 weeks of pregnancy due to fetal kidney risks.”
Both chunks are about ibuprofen safety, so vector search ranks both highly. But only one answers the question the user asked. The pipeline can’t tell the difference, and confidently hands back the wrong chunk.
This post explains why that happens, and how re-rankers fix it.
I published a companion GitHub repo with a runnable notebook that demonstrates three common ways vector search fails (negation, missed constraints, topic-over-answer) and shows the re-ranker fixing them.
The Library Analogy

A giant library. Every book has many sections, each holding facts, claims, definitions, maybe answers to questions someone will ask one day.
You need to make it searchable. So you hire a librarian to summarize every section on a small card. The catch: she writes the cards before any reader walks in, with no idea what readers will ask.
What’s the best she can do? Write a high-level summary. “This section discusses the causes of type 2 diabetes.” “This section covers lithium-ion battery thermal runaway.”
These cards capture the topic. They don’t capture every fact, every constraint, every nuance. A one-line summary loses detail by definition.
That’s what an embedding model does. Feed it a chunk of text and you get back a vector: a list of numbers, usually between 384 and 1536 long, depending on the model. The vector is the digital summary card. It captures roughly what the chunk is about, written before any question is asked.
A reader walks in with a question. She writes that on a card too. The librarian compares the question card against every section card and hands back the closest matches.
That’s vector search. Embed the question, compute similarity against the pre-computed chunk vectors, return the top matches.
How Embedding Models Work, and Where They Break
An embedding model is a transformer encoder, a model that reads text and produces numbers that represent it. In vector search, the encoder runs twice: once on each chunk (ahead of time, to build the index) and once on each query (at search time). The two outputs (vectors) are then compared by a similarity score computed outside the model.
This architecture is called a bi-encoder. The model never sees the query and chunk together.
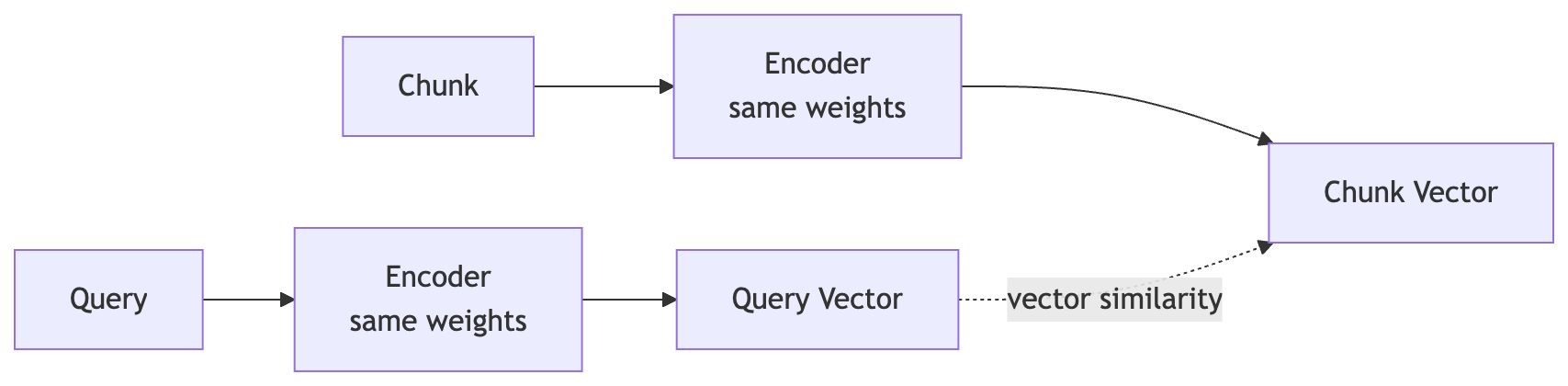
The bi-encoder design is what makes vector search fast. You pre-compute every chunk vector once, store them in an index, and reuse them for every future query. At query time, you embed the question once and search across millions of vectors in milliseconds.
The architecture has two compressions, both lossy:
Chunks get compressed before anyone asks a question. A chunk holds several facts, possibly answers to several questions, plus context and noise. All of it squashes into one vector: roughly the aggregate of everything in the chunk, in the model’s coordinate space (often called “semantic space” because chunks with similar meanings land near each other). No fact gets its own representation. The model doesn’t know which fact will matter for a future question, so it can’t favor any.
Questions get compressed without knowing which document they’ll meet. Same problem on the question side. Intent, constraints, framing: all reduced to one topical fingerprint. When you embed “What was Apple’s revenue in Q3 2024?”, the vector mostly represents “Apple revenue recent quarter.” “Q3 2024” barely registers.
You’re comparing two lossy fingerprints. Nothing in your pipeline ever looks at the raw question alongside the raw chunk.
Three Common Ways Vector Search Fails
These are three canonical failure modes the companion repo shows. Each maps to a query in the demo notebook.
Negation gets lost.
Question: “Is ibuprofen recommended late in pregnancy?”
Chunk A: “Ibuprofen is widely used for general pain relief.”
Chunk B: “Ibuprofen is not recommended after 20 weeks of pregnancy due to fetal kidney risks.”
Both chunks share the same vocabulary about ibuprofen, so vector search ranks them similarly. But only Chunk B answers the question about late pregnancy; Chunk A answers a different question, about general pain relief. The model can’t tell the difference.
Constraints get washed out.
Question: “What was Apple’s revenue in Q3 2024?”
Chunk A: “Apple’s Q2 2023 revenue grew significantly, reflecting strong iPhone sales.”
Chunk B: “Apple reported Q3 2024 revenue of $85.8 billion.”
Both chunks share the same vocabulary about Apple and quarterly revenue, so vector search ranks them similarly. But only Chunk B answers the question about Q3 2024; Chunk A answers a different question, about Q2 2023. The exact quarter barely registers in either vector.
Topic match beats answer match.
Question: “How do I reset my password?”
Chunk A: “Password security is critical. Use strong passwords, enable 2FA, never share passwords...”
Chunk B: “To reset your password, click ‘Forgot Password’ on the login page...”
Both chunks share the same vocabulary about passwords, so vector search ranks them similarly. But only Chunk B answers the question about resetting a password; Chunk A answers a different question, about password security best practices.
Every failure traces back to one source: vector search ranks chunks by topical overlap, but topical overlap doesn’t tell you which question each chunk actually answers. The fix is in the architecture.
The Re-Ranker
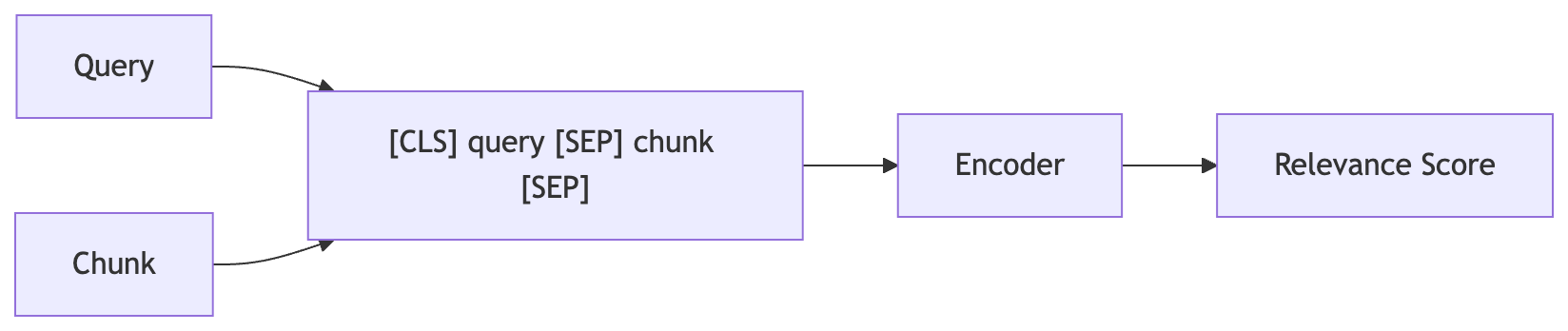
The architectural fix is to bring the question and the chunk inside the same model. Instead of comparing two vectors outside the model, a re-ranker reads the question and a candidate chunk together in one forward pass, and scores how well the chunk answers that question. It compares them word by word.
This architecture is called a cross-encoder, because the query and passage attend across each other inside the model. A re-ranker is the API around it: you send a query and a list of candidates, and the service pairs the query with each candidate internally, runs the cross-encoder on every pair, and returns the sorted list.
The cross-encoder sees which chunk answers the asked question, even when several chunks share the same vocabulary: late-pregnancy safety vs. general use, Q3 2024 vs. Q2 2023, password-reset instructions vs. password best practices. It returns a relevance score for every pair: higher means more relevant.
If you were searching by hand, you’d do the same thing. You wouldn’t write summary cards in advance. You’d grab a stack of candidate books, sit down with the question in front of you, and read each passage with the question in mind. Then you’d rank them.
Why joint processing works
The cross-encoder’s joint processing, reading the query and passage in one forward pass, works because of the transformer’s attention mechanism. At every layer, each token weights its relationship to every other token in the input. With the question and chunk in the same input, the model can match “Q3 2024” in the question against “Q3 2024” in one chunk and “Q2 2023” in another, and tell which one the question is asking about.
A bi-encoder runs two separate forward passes. The model has no chance to compare words across them. The comparison happens at the end, between two finished vectors, after the word-level details have been compressed away.
Joint processing means more information flowing through the same computation.
How does the model know which words are query and which are passage (answer chunk)?
If both texts share one input, how does the model tell query from passage?
Two special tokens. [CLS] marks the start of the input. [SEP] marks the boundary between query and passage. The combined input looks like this:
[CLS] is ibuprofen safe during late pregnancy ? [SEP] ibuprofen is not recommended after 20 weeks . [SEP]The model processes both texts together, but always knows which words came from the query and which came from the passage.
Input and output
A re-ranker typically takes 10 to 100 candidate passages per query. It returns a relevance score per passage. Some models return values between 0 and 1; others return unbounded numbers, often in the -10 to +10 range, where higher means more relevant. Most also return a sorted index list so you know which score belongs to which passage.
You sort by score and keep the top N for your LLM.
One constraint: most cross-encoders cap input at 512 tokens for the combined query plus passage. If your chunks are long, the end gets truncated, which quietly degrades quality. Keep chunks under about 400 tokens, or pick a longer-context re-ranker like bge-reranker-v2-m3, which supports inputs up to 8192 tokens (though it’s fine-tuned at 1024, so very long inputs see diminishing returns).
Bi-encoder and cross-encoder, side by side
The bi-encoder and the cross-encoder are built on the same transformer encoder, used differently. The bi-encoder runs it twice and compares vectors outside the model; the cross-encoder runs it once and judges relevance inside.

The bi-encoder gives up precision to search at scale. The cross-encoder gives up scale to score with precision. Each makes up for the other’s weakness, which is why production RAG pipelines use both, in that order.
In your pipeline, the re-ranker call sits between vector search and the LLM:

Why Not Use Re-Rankers for Everything?
A bi-encoder lets you pre-compute every chunk’s vector once and index it. At query time, you embed the question once and search across millions of vectors in milliseconds.
A re-ranker can’t be pre-computed. Every (query, passage) pair runs through the full model at query time. Re-ranking a million chunks per query would take hours.
So you combine them:
Retrieval with a bi-encoder. Pull 50 to 100 candidates from the full corpus. Cast a wide net. The goal is recall: make sure the right chunks sit somewhere in those 100. (Recall measures how often the right answer appears in your results at all; precision measures how often the top result is right.)
Re-ranking with a cross-encoder. Score each of the 50 to 100 candidates against the question. Sort. Keep the top 5 or 10 for the LLM.
Speed at the recall stage, precision at the ranking stage. The two-stage approach mirrors the human librarian: narrow with rough signals, then read closely to pick the winners.
Why Not Just Let the LLM Filter for Relevance?
A reasonable question: why add a re-ranker at all? Why not send the top 50 chunks from vector search straight to the LLM and ask it to use only the relevant ones?
You can. It loses on accuracy, cost, and latency.
Accuracy. LLMs are bad at picking the most relevant chunks when many candidates sit in the same context window. The “Lost in the Middle” paper (Liu et al., 2023) showed that across GPT-3.5 and several other models, accuracy is highest when the relevant chunk sits at the very start or end of the context, and drops 20 to 30 percentage points when it sits in the middle. Follow-up work has confirmed the same pattern on GPT-4, Claude, and Gemini, even as their context windows grew past 100K tokens. A cross-encoder scores each (query, chunk) pair on its own. Position in a list never enters the math.
Cost. Sending 50 chunks (about 25,000 tokens) to a frontier LLM on every query runs roughly 10x the input-token cost of re-ranking first and sending only the top 5 (about 2,500 tokens). At 10,000 queries a day, the gap adds up.
Latency. Two stages are usually faster than one. A re-rank pass takes 100 to 300ms. Sending 25,000 tokens to a frontier LLM typically takes several seconds for the first token; 2,500 tokens takes one or two. Re-ranker plus a smaller LLM call ends up noticeably faster end to end.
A re-ranker is small, fast, and trained on millions of (query, doc, relevance) pairs to do one job. An LLM is trained to write fluent answers. Asking it to also act as a precise relevance classifier inside the same call moves the work to a slower, costlier, less accurate component.
The exception is small candidate sets. With only 3 to 5 chunks, position bias is mild and re-ranking adds little. Skip it. Past about 10 candidates, the gap opens fast.
When a Re-Ranker Isn’t Worth It
Re-rankers have their cost. Before you add one, check whether the cost is justified:
Tight latency budgets. Re-ranking adds 100 to 500ms per query. If your end-to-end budget is under a second, that hurts.
Mostly exact-keyword lookups. For product SKUs, error codes, and literal strings, BM25 (a keyword algorithm that scores documents by term frequency and rarity, used by most search engines before embeddings) often beats vector search on its own.
High query volume. API re-rankers charge per call. At millions of queries per day, costs add up. Self-host an open-source re-ranker if volume is high.
If none of these apply, and your current pipeline returns “close but not quite” results, a re-ranker is worth exploring.
Re-Ranker Options
A short list of re-rankers in active use. They fall into two buckets: hosted APIs (call an endpoint, pay per query) and open-weights models (download and run yourself).
API-based:
IBM watsonx.ai Rerank. Hosts several cross-encoder models.
Cohere Rerank. Current models include
rerank-v3.5(4096-token context) andrerank-v4.0.Jina Reranker. Available as API or self-hosted.
Voyage Rerank. API-based; current models include
rerank-2andrerank-2.5.
Open weights, self-host:
BAAI/bge-reranker-v2-m3. Multilingual; supports inputs up to 8192 tokens.mixedbread-ai/mxbai-rerank-large-v2. Supports inputs up to 32K tokens.cross-encoder/ms-marco-MiniLM-L-6-v2. 6-layer MiniLM cross-encoder trained on MS MARCO; commonly used as a starter model.
Summary
Vector search compares fingerprints, not specifics. It compresses every chunk and every question into their vectors, then matches them by topical overlap. That works for “what is this about?” It fails when negations, exact constraints, or specific entities decide the answer.
A re-ranker reads the question and the chunk together, word by word, and scores how well one answers the other. Vector search narrows the corpus to about 50 candidates; the re-ranker picks the winners. Rough filtering, then careful reading.
The payoff is concrete: a correct chunk ranked 30th by embedding similarity gets promoted to position 1 or 2 by the re-ranker. That’s the precision gap the cross-encoder recovers.
If your RAG pipeline returns “close but not quite” answers, try a re-ranker next.
Try This
Clone the companion repo: github.com/shaikhq/rag-reranker-demo. Run the notebook end to end, see the three failure modes, see them fixed.
Swap in your own PDF and rerun. The same lift usually shows up on real data.
Wire a re-ranker (watsonx.ai, Cohere, or a self-hosted BGE model) into your pipeline behind a feature flag.
Measure top-1 and top-5 accuracy on a small eval set, with and without re-ranking.
Tune the candidate count (50 vs 100 vs 200) and watch the precision-versus-latency curve.