

Understanding Machine Learning Model Types
How to pick the right one for your task


There is not one algorithm that’s going to solve all your problems. Think of it like wanting to unscrew something. You have a toolbox with different sized screwdriver bits, and you have to find the right one for the screw in front of you. Machine learning works the same way. You have to see what kind of data you are dealing with and the learning task at hand, and then find the right tool, the right algorithm, the right AI technique.
Some data sits neatly in rows and columns. Other data is a mess of text, images, and files. Each needs different tools to unlock its value.
In this article, I’ll walk you through the main types of machine learning models and learning tasks. This is not meant to be exhaustive. I want to cover the more representative models so you have a solid foundation.
First Things First: Structured vs. Unstructured Data
Before we dive into the model types, we need to understand the two broad categories of data we deal with: structured data and unstructured data.
Structured data is the kind of data stored in relational schemas, it’s not free form. It comes with a structured format. You have a table with a list of columns, and each column has some attribute values. Maybe an employee table with employee name, join date, department, and salary. Everything is fixed with columns and rows. You can make a lot of assumptions about the data structure, and you have much more predictable characteristics because it’s a fixed structure.
I find this analogy useful: think of going to a library where all the books are organized on shelves. If you’re looking for a specific book, you ask the librarian, and they just look up and tell you exactly which shelf you can find it on. Everything is very neatly organized.
Unstructured data, on the other hand, is like a very messy situation, maybe people who just returned all the books have left them haphazardly in a pile. You don’t know where you can find anything. Unstructured data includes things like free-form text, images, audio, and video.
How Machine Learning Models Learn
Before we look at specific model types, you need to understand the two fundamental ways models learn from data: supervised and unsupervised learning.
Supervised Learning
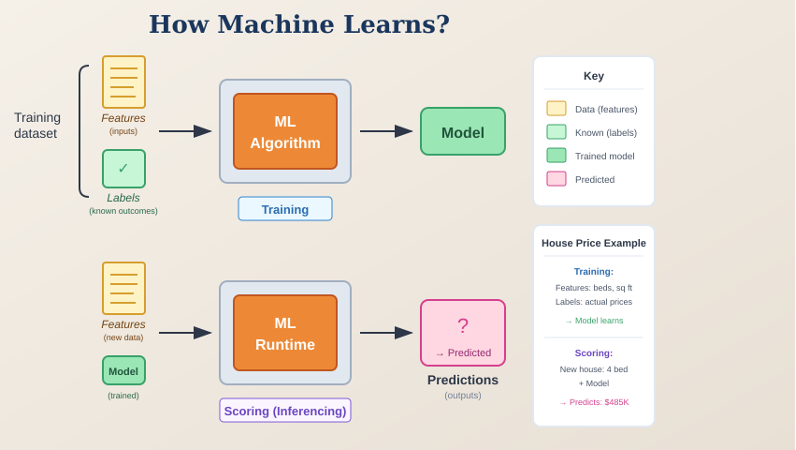
In supervised learning, you provide the model with examples that include the correct answers. You need two types of content in your data.
Features: A set of attributes that describe something. For example, if you want to predict customer churn, you might collect which products customers are using, how many licenses they have, how many times they called support.
Labels/Targets: The outcome, what actually happened. When the time came for renewal, did this customer renew or not?
You collect input and output combinations for many examples, then give this to a learning algorithm. The algorithm figures out how to map inputs to outputs.
A good way to think about it: remember equations like y = constant + a₁x₁ + a₂x₂?
The machine learning algorithm learns this kind of mapping from your data.
Once trained, for future events where you only know the inputs, you plug them into the model and it predicts the output. This process is called scoring or inferencing.
Self-Supervised / Unsupervised Learning
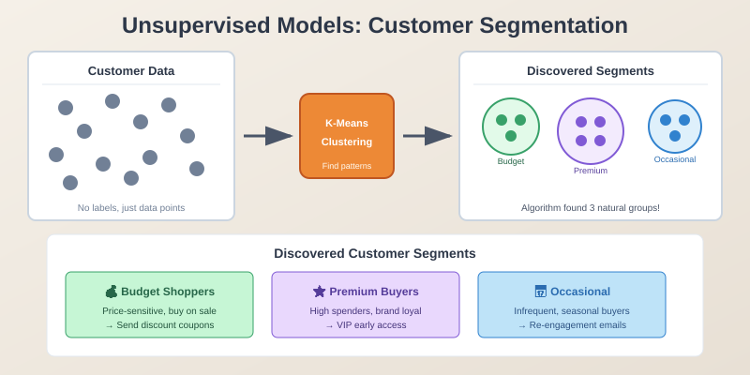
In self-supervised learning, you don’t provide the correct answers. You give the model data and let it find patterns or groupings on its own. You only have features, no labels.
Clustering is a common self-supervised technique. Algorithms like k-means clustering group similar data points together without being told what the groups should be. For example, you might have customer data and want to discover natural segments. The algorithm analyzes the features and groups similar customers together. Marketing teams often use this to identify customer personas they didn’t know existed.
Predictive Models
Predictive models use supervised learning to give you predictions about future outcomes. Classification, regression, and time series forecasting all require labeled training data.
Classification
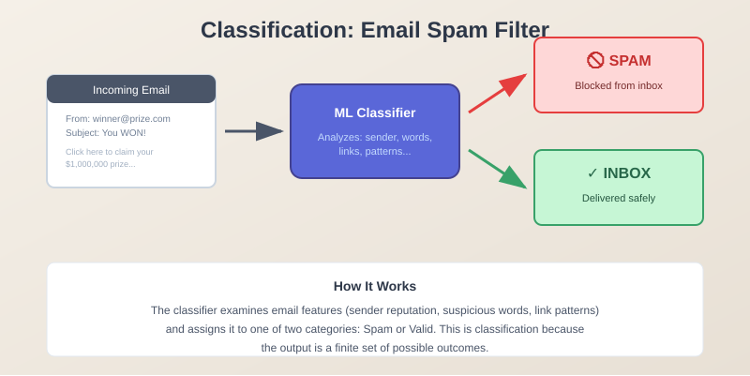
For structured data, one kind of prediction you can make is the category or class of something. A classic and familiar example: you have an email, and you want to classify it into one of two categories, valid email so it can get to your inbox, or spam. That’s what Google has done with their spam folder and inbox. They have a spam classifier that looks at each email and a set of characteristics (the features), and based on this, classifies each email as spam or valid (the label).
Another example is fraud detection. You go to your grocery store and swipe your credit card to pay. Behind the scene, it goes to the credit card authorization system, which quickly checks whether this transaction is valid or fraudulent.
Why is this called classification? Because this model is making some conclusion about the input, a structured row of data, and saying that this record belongs to one of a finite set of classes. It’s either valid or fraudulent. You can have multiple classes, but it’s always a finite set of possible outcomes. That’s called classification.
Regression
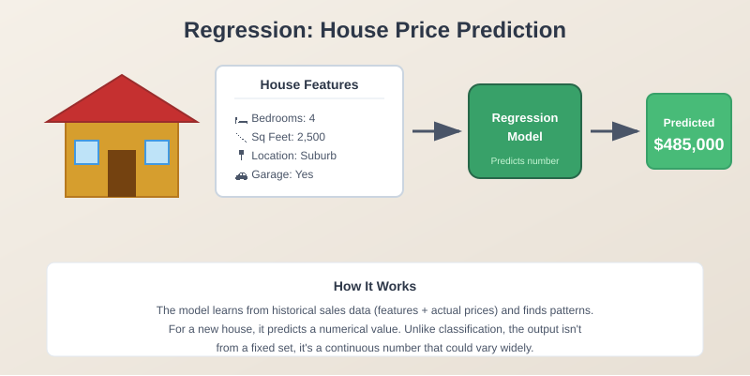
The other kind of predictive model you can build with structured data is a regression model. A common example is predicting house prices. You want to predict what a house will sell for based on how many bedrooms it has, the square footage, and other features.
You can train a machine learning model with houses that were sold in a neighborhood, their features and the price at which each was sold. You give all these to a learning algorithm, and then you have a learned regression model. Next time a house that has yet to be sold comes along, you just collect its description and attributes, give it to this model, and the model gives you a numerical value.
Unlike classification, where you predict from a finite set of values, here your model is predicting a number that could vary widely. The number is not coming from a fixed set of values. This kind of model is called a regression model.
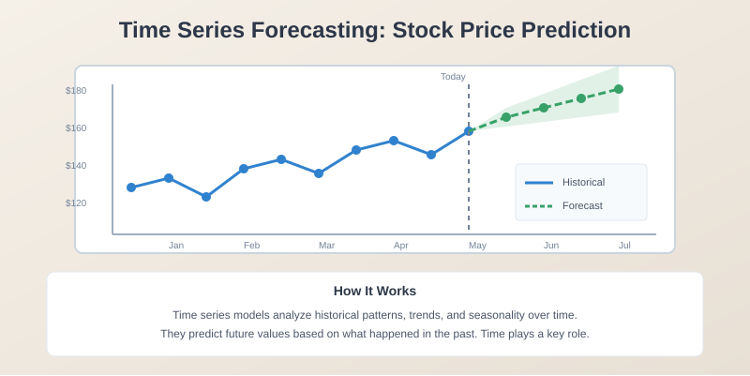
Time Series Forecasting
Another type of predictive model is time series forecasting. You might want to predict stock prices based on events and factors, or weather forecasting. There’s seasonality, there are variables and factors you’re collecting over time, what happened, what are some of the things that occurred. Based on this, you’re predicting future values. Time plays a role in these models, that’s what makes them different from standard regression.
Predictive Models for Unstructured Data
For unstructured data, similar predictive models exist, but they work with different types of input.
Image classification: You might want to classify pictures, give a machine learning model images and have it learn to predict whether a picture is of a cat, a dog, or some other animal.
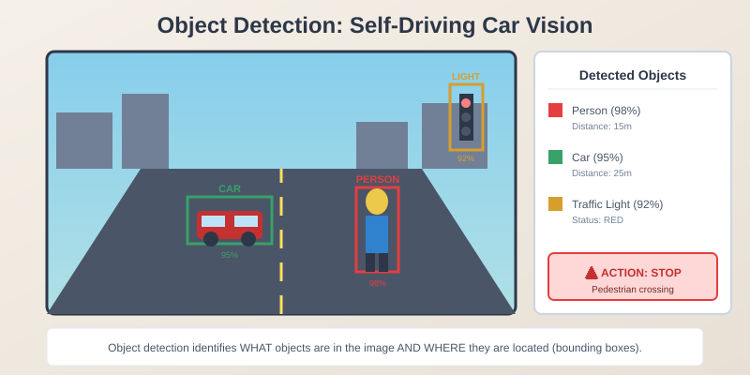
Object detection: A self-driving car is constantly taking pictures of what’s in front of it and around it, identifying objects and their locations. It’s not sufficient to just know that there’s an object in front of the car, it also needs to know the location of that object.
Text classification and sentiment analysis: Maybe you have product reviews and you want to predict if the customer is happy or not. You can analyze their text comment and classify whether they’re a happy customer or not.
Generative Models
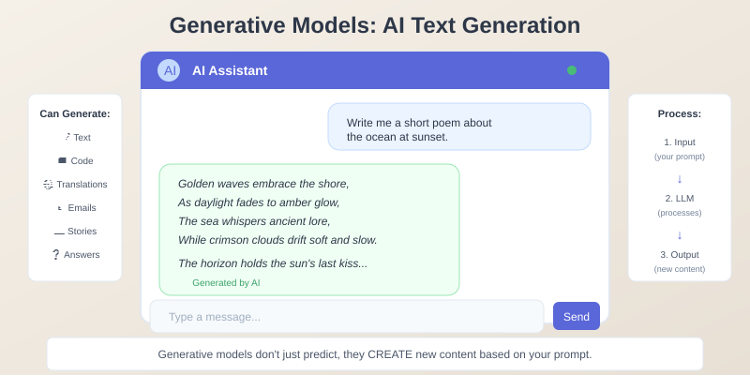
This is the category that’s been very popular in recent years, the large language models (LLMs), such as ChatGPT, and all these generative AI models. This kind of model is not just predicting based on an input. It takes a prompt and then creates content for you.
Text generation: You can give a prompt and all of a sudden get a long, AI-generated text. It can generate articles, very human-like responses, and more.
Language translation: You speak in one language, and it gets translated into another. Services like Google Translate use neural machine translation models for this.
Code generation: You can generate code using AI. IBM Project Bob, Claude, Gemini, ChatGPT, there’s a lot of code generation happening with these tools.
Image generation: These models can also generate images based on text prompts.
What Makes Large Language Models “Large”?
Two things make them large: massive training data from sources like Wikipedia, books, and web pages, and billions of parameters (the internal variables the model learns during training). GPT-3, for example, has 175 billion parameters. This scale allows LLMs to capture intricate patterns in language.
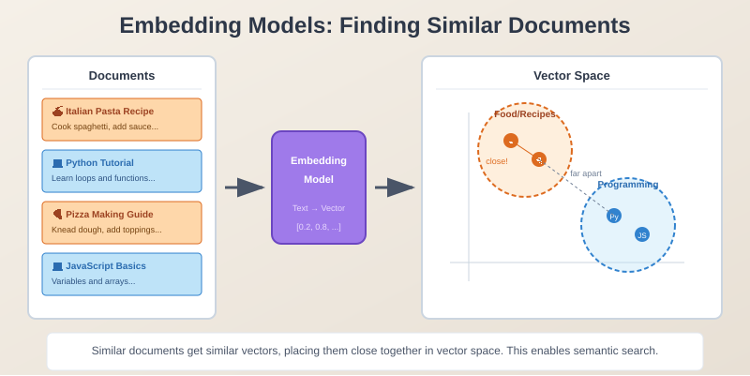
Embedding Models
Embedding models are a different kind of AI model. They don’t produce something immediately consumable like a prediction or generated text. Instead, they give you an intermediate representation called a vector, which is essentially a list of numbers that captures the meaning or characteristics of your data.
For example, each of us has certain background attributes, the field we work in, years in our career, our university education. If we want to learn which of us are closer to each other based on our technical or academic background, we could use some kind of embedding model to take a text description of who we are, and based on this, it gives a vector representation. Those of us who are similar are expected to have similar vector representations.
Similarly, you can have a list of documents or articles, vectorize them, and see which articles are similar to each other. Maybe a subset are food blogs and others are technical blogs, you expect articles in the food blogs to have similar vector representations. You can do the same with images.
With multimodal embedding, your content is a mix of text and image, and you can vectorize it to do semantic search, not just plain text-based matching, but vector-based semantic search.
Choosing the Right Model for Your Problem
When you’re approaching a problem, ask yourself three questions:
What kind of data do you have? Structured data (tables with rows and columns) works well with traditional machine learning. Unstructured data (text, images, audio, video) typically requires deep learning approaches.
Do you have labeled data? If you have historical data with known outcomes, you can use supervised learning (classification, regression). If not, consider unsupervised approaches like clustering or embedding models.
What kind of output do you need? This is often the deciding factor. Use the table below as a quick reference.
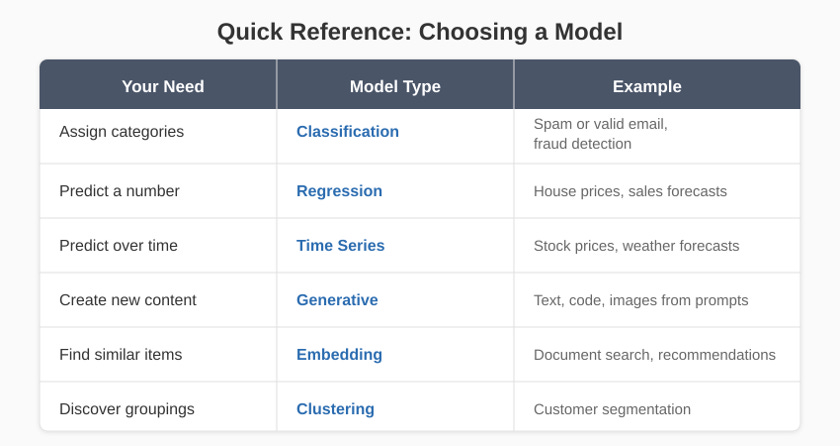
The temptation today is to reach for LLMs for everything. But LLMs are just one drawer in the toolbox. For structured, tabular data, traditional machine learning algorithms are often faster, simpler, and more accurate. The skill isn’t knowing the most powerful tool. It’s knowing which tool fits the problem in front of you.
Solid primer on model selection. The library/messy pile analogy for structured vs unstructured data is spot-on. One thing that really resonates is the point about not defaulting to LLMs for everything, I've seen teams waste weeks trying to force GPT-4 onto tabular forecasting problems when a simple XGBoost model would've shipped faster and performed bettter. The decision tree at the end is practical for those who dunno where to start.