

Two Roads to Real-World AI: Navigating Structured and Unstructured Use Cases
Learn how to match AI techniques to data types — with real-world use cases in structured prediction and unstructured semantic retrieval

Many AI discussions skip straight to the tools: Python libraries, GPU clusters, pre-trained models. But if you step back, almost every useful AI system falls into one of two categories — structured or unstructured — depending on the shape and semantics of the data.
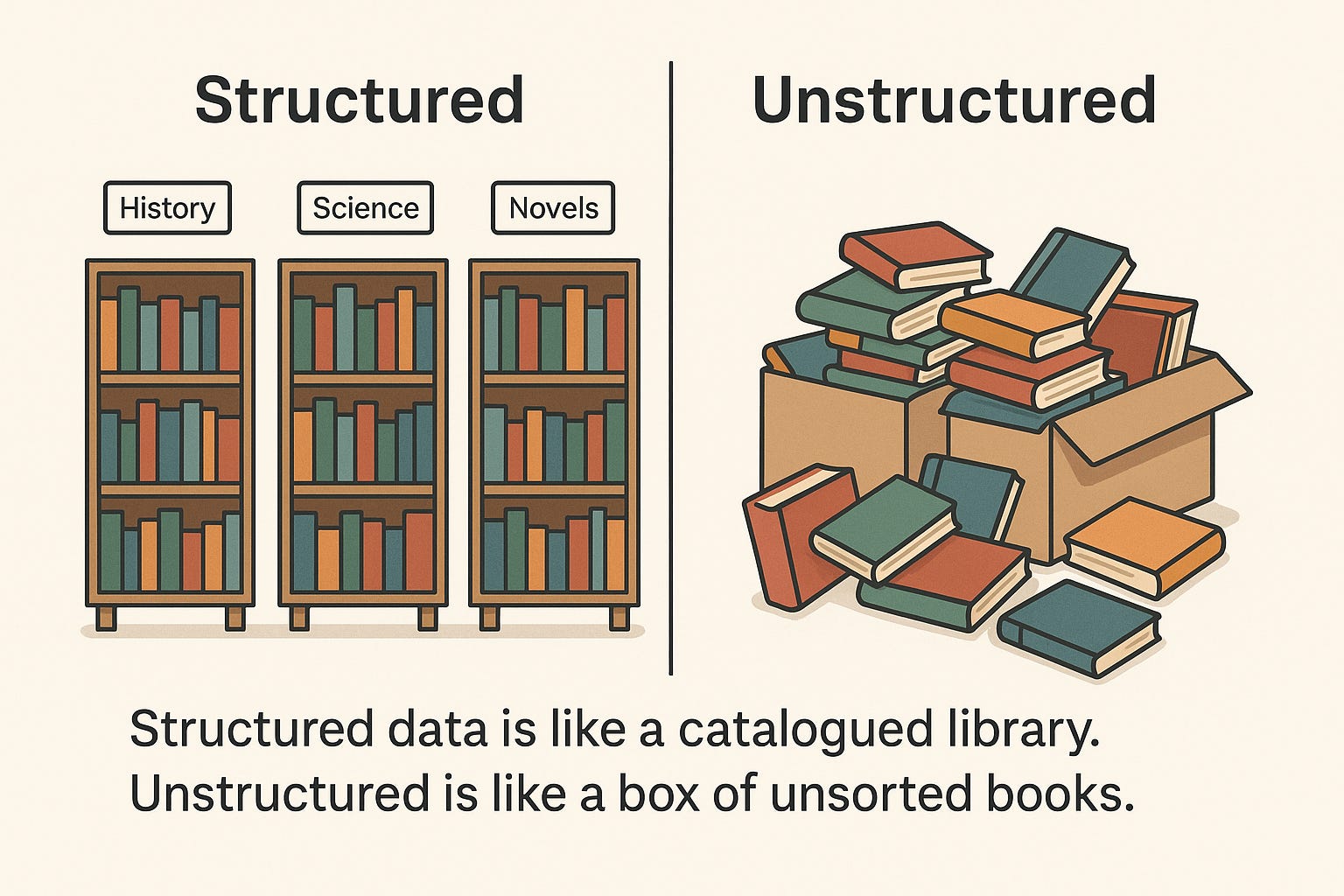
Think of your data like a library:
In a structured system, everything's in order — books neatly shelved by topic, titles searchable by a catalogue.
In an unstructured world, the books are dumped into boxes. Still valuable — but hard to find.
To build AI systems that work, you need different workflows for each.
This post walks through two foundational AI workflows. One grounded in tables and historical labels. The other rooted in freeform text, images, and semantic search. Together, they cover the spectrum of real-world AI systems.
Structured Data: A Clean Path to Early Wins
Let’s start with what’s familiar: structured data.
This is the kind of data most enterprise systems already collect and store in relational databases. Think: customer IDs, license usage metrics, support ticket timestamps — all organized in rows and columns.
Because the data is already well-formed and clean, it lends itself well to traditional machine learning, particularly:
Supervised Learning: Often called "labeled" learning. We use historical data with known outcomes to predict future results.
Self-Supervised Learning: Previously known as unsupervised learning. It discovers hidden patterns or clusters in the data without explicit labels.
Supervised ML Use Case: Modeling Risk of License Non-Renewal
Imagine you’re a data scientist. You receive a dataset of customers, their licensing behavior, product usage patterns, and support interactions. Your task: identify customers who might reduce their license quantity in the next renewal cycle.
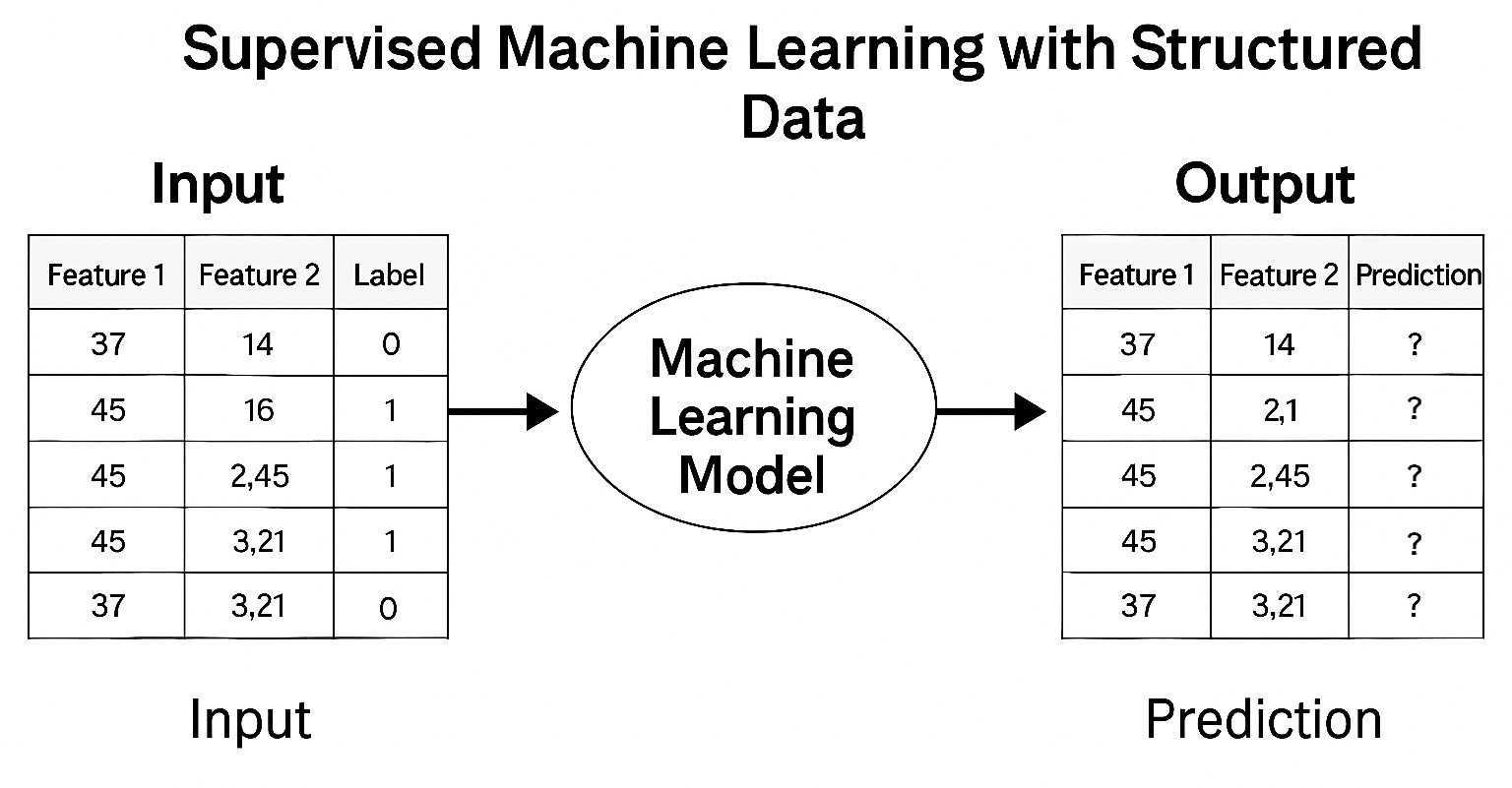
You begin by organizing the dataset into two parts:
Features: all available signals from a defined historical period (e.g., January 1 to December 31, 2024). This includes usage data, support cases opened, download frequency, etc.
Labels: the outcome — whether the customer reduced their license on renewal (e.g., on January 1, 2025).
With this setup, you build a predictive model using any modern ML tool or platform. The model learns from labeled historical rows and outputs a formula that, given a new set of inputs (usage patterns, support interactions), predicts the label (license reduction risk).
This is supervised learning. It requires labeled historical data, and its goal is to anticipate the future — allowing your business to act early.
Even if this exact scenario isn't yours, you can adapt similar workflows to build your own models with tools like SQL-based ML extensions, Python-based notebooks, or end-to-end cloud AI platforms.
What If Labels Are Missing?
Now imagine a twist: you have the same customer dataset — usage patterns, license quantities, support activity — but you're missing the outcome label. You don’t know who reduced their license.
Can you still get insights? Absolutely.
You turn to self-supervised learning.
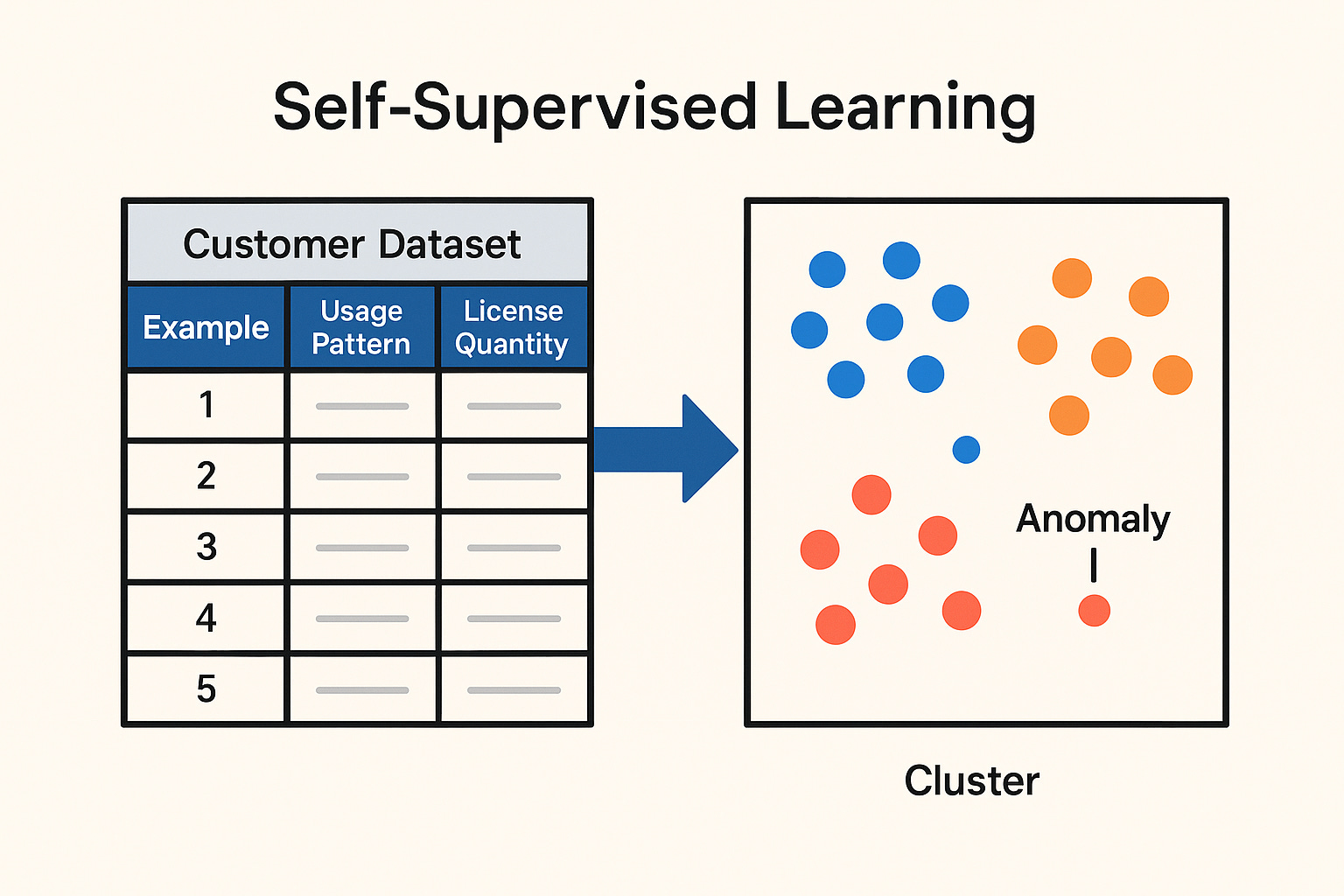
You start by exploring natural groupings in the data. Maybe some customers have steadily increasing usage. Others have sporadic or declining engagement. You cluster customers based on feature patterns using algorithms like k-means or DBSCAN.
This lets you:
Identify cohorts of customers with similar behaviors
Detect anomalies — those who deviate sharply from their cluster norm
Discover latent segments that might inform targeted interventions
For example, a cluster of low-usage but high-license customers might signal a group at risk of attrition. Even without explicit churn labels, these insights help your team ask better questions and prioritize deeper investigation.
Self-supervised techniques turn structure into signal — all without needing ground truth outcomes.
Unstructured Data: The Messy World
Now let’s turn to unstructured data — the kind not stored in neat rows and columns.
Emails, support tickets, PDFs, logs, and images often live in cloud volumes or blob storage. These datasets are difficult to search, process, or categorize using traditional machine learning. There’s no fixed schema, no consistent formatting.
Here’s where advanced AI techniques come into play, especially those behind large language models (LLMs).
Unstructured Data Example Use Case: Semantic Search with Vector Retrieval
Picture this: you have a large technical document composed of multiple paragraphs. You want to answer a user’s question using that document — but the answer isn’t phrased using the same words as the question.
Humans resolve this easily. Machines, however, struggle unless they understand meaning beyond surface keywords.
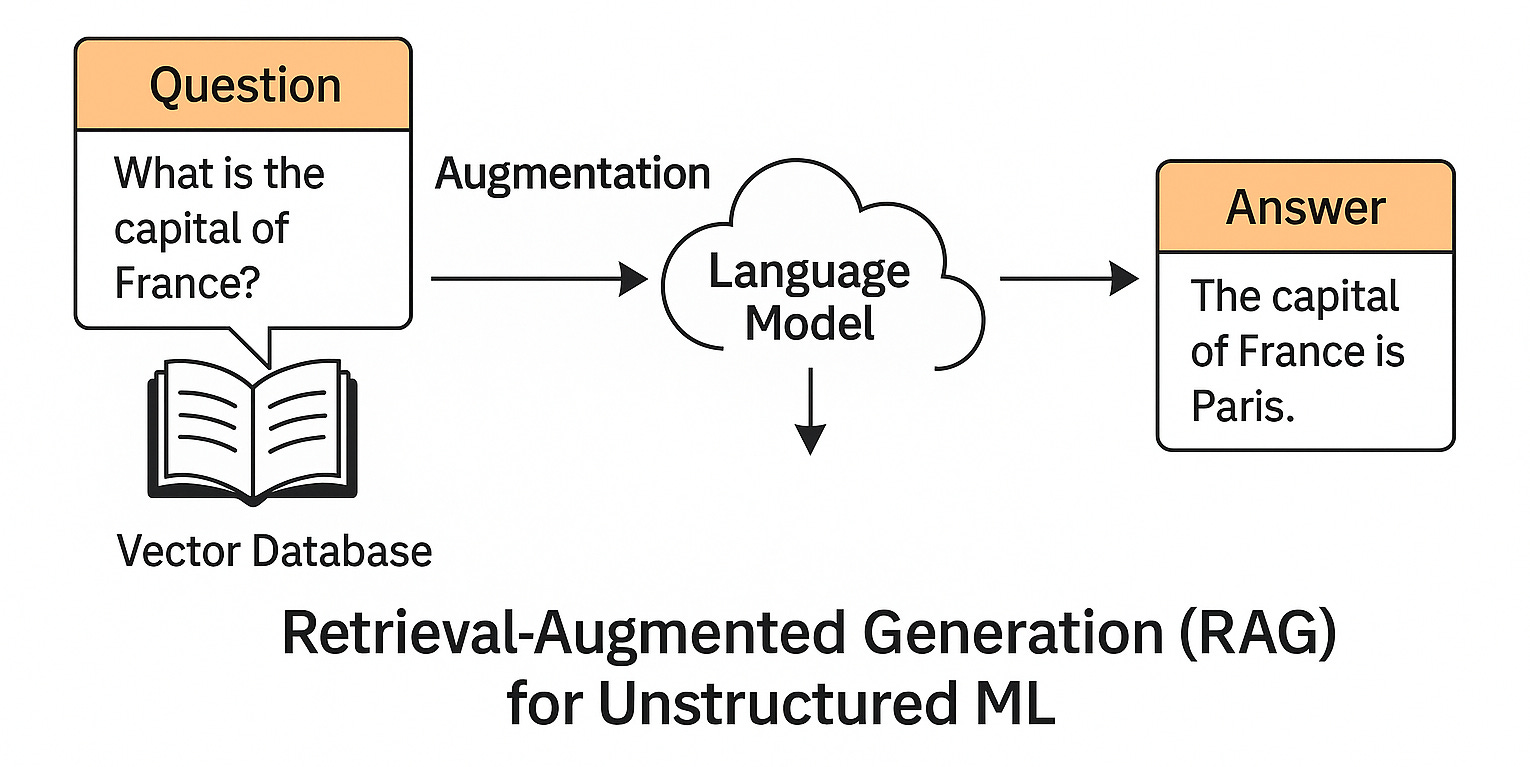
Here’s the workflow that solves this:
Segment your text into meaningful passages or paragraphs.
Generate vector embeddings for each segment using a pre-trained model. These embeddings are high-dimensional representations capturing the meaning of the text.
Vectorize the query or question using the same model.
Perform a similarity search to find the top segments that semantically match the query.
These vectors are generated using models trained on vast internet-scale data (like Wikipedia), so they understand context, synonyms, and conceptual relationships. For example, “iPhone” and “Apple phone” will point to the same underlying concept.
Once you retrieve the top matching segments, you can feed them to an LLM to synthesize a coherent response. This combination of retrieval and generation is known as retrieval-augmented generation (RAG).
Where to Go from Here
Structured data often delivers the quickest wins — it’s easier to model. If you’re trying to show early value, start there. A focused prediction model based on clean, tabular data can immediately improve decisions like churn risk, lead scoring, or renewal prioritization.
But that’s only part of the picture.
In parallel, begin exploring the unstructured data you already collect — notes, emails, call summaries, reports. Pick a narrow, high-friction task where this messy data plays a role, and build a small prototype. For example, use vector search to match queries to documents or retrieve relevant snippets from notes.
You don’t need to solve unstructured data end-to-end. Just test one small use case. See if you can reduce search time, improve relevance, or surface overlooked insights.
In this post, we walked through both paths:
A structured prediction model for renewal risk
A vector retrieval system for semantic search
Both are useful. Both are feasible.
The next step isn’t choosing one — it’s progressing on both, each at the right scale.
Start with one structured problem you can model immediately — and explore one unstructured workflow in parallel.