

The Step Most AI Portfolios Skip
If you are preparing for an AI role, you have likely built something solid. Here is what to add that shows you can think like a professional engineer.


Students reach out to me regularly. They share their portfolios, ask for feedback, want to know why they are not hearing back from applications.
I look at their work. And almost every time, I see the same pattern.
A RAG pipeline. An AI agent. A classification model. Clean code, decent README, maybe a demo video. And then it stops there.
Building something real takes effort, and that effort is worth acknowledging. But there is a next step most students have not been shown, and that gap is what is holding them back.
That is what this post is about.
The question that separates candidates
When I review a portfolio as an AI architect, I am not only asking can you build this? I am also asking do you know if what you built is any good?
Those are not the same question. And in my experience, most portfolios only answer the first one.
Think about what the job actually involves. You will not be handed tutorials to replicate. You will be handed a system that partially works and asked to improve it. Or you will build something from scratch and be responsible for demonstrating it meets a quality standard before it ships.
The question your portfolio needs to answer is: can you take something that partially works and make it measurably better?
What this looks like in practice
Let us use RAG as the example. It is the most common AI portfolio project I see right now, and a good one to learn from.
You built a RAG pipeline. It retrieves documents and generates answers. You tested it with a few queries and the responses looked reasonable.
But do you actually know how well it is working?
There is an open source evaluation framework called RAGAS, published at EACL 2024, built specifically to evaluate RAG systems. It gives you measurable scores on dimensions that matter in production:
Faithfulness measures whether the model’s answer is grounded in the retrieved documents, or whether it is generating claims the documents never supported. This is how you detect and quantify hallucinations.
Answer Relevancy measures whether the response actually addresses what the user asked.
Context Precision and Recall measures whether your retriever is surfacing the right document chunks in the first place.
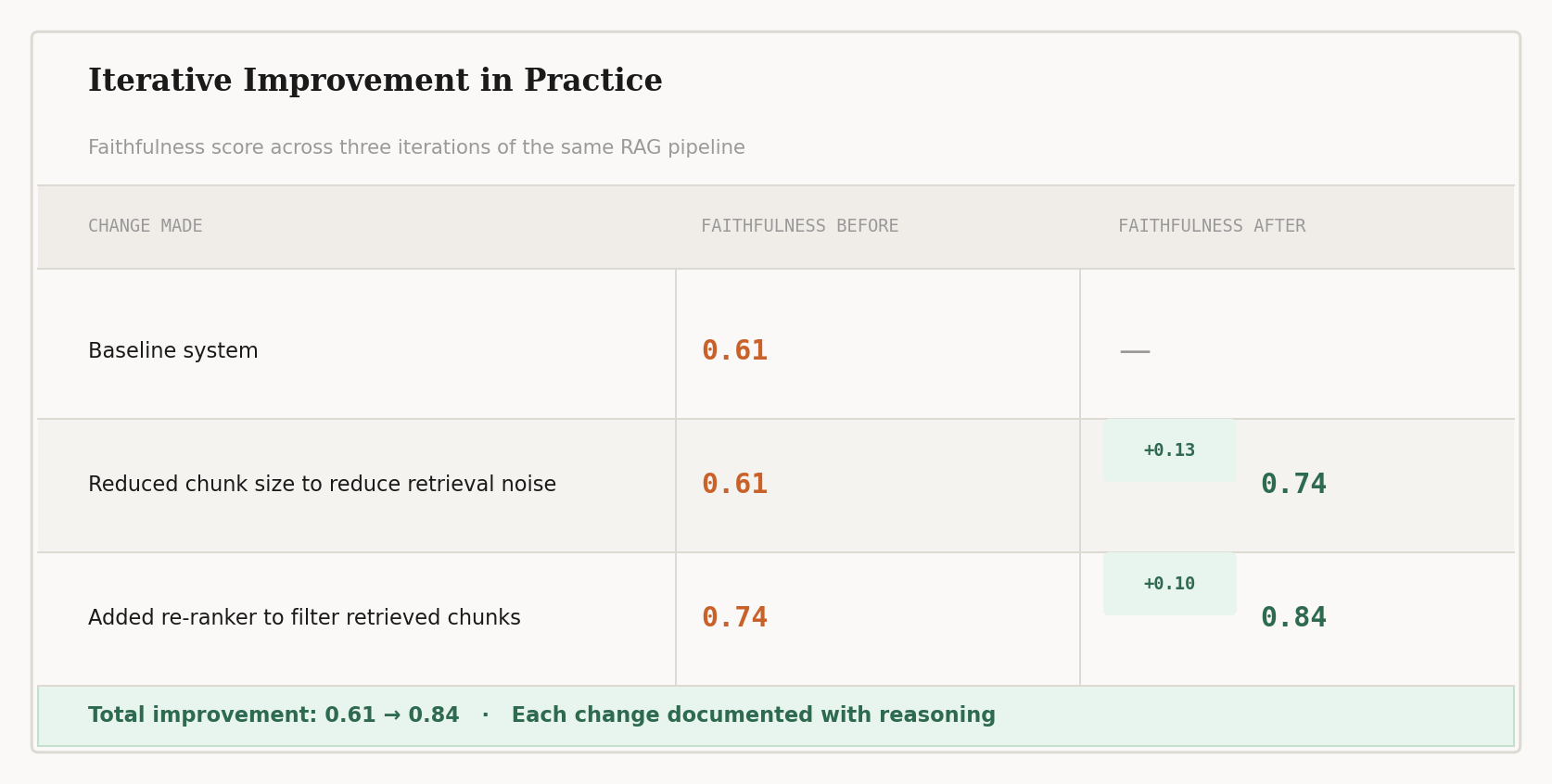
You run your system through RAGAS and get a faithfulness score of 0.61. That means roughly 4 in 10 claims your system generates are not supported by the retrieved documents. For most production use cases, that is not acceptable.
[What most portfolios show vs. what hiring managers are also looking for]
So you investigate. You find your chunk size is too large and the retriever is returning loosely related content alongside relevant content. You reduce the chunk size. Faithfulness moves to 0.74. You introduce a re-ranker to improve which chunks reach the model. Now it is 0.84.
You document every step. The baseline score, what you changed, why you made that change, and what improved as a result.
That documented process, not just the final system, is what demonstrates engineering thinking.
This applies beyond RAG
If you are building a classification model, it is worth asking: do you know your precision, recall, and F1 score, and do you understand which one matters most for your specific use case?
If it is a regression model, can you explain what your RMSE is telling you about your system’s real world behaviour, beyond the formula itself?
These are not advanced topics. They are foundational to working with models professionally. And developing fluency with them early will serve you well throughout your career.
There is a principle worth holding onto: you cannot confidently claim something works if you have no definition of what working means.
I came across this idea early in my career through a book called Exploring Requirements: Quality Before Design by Donald Gause and Gerald Weinberg. I read it years ago and it shaped how I think about building systems. Their core argument is straightforward: define quality before you design, not after. The book was written in 1989 about software engineering. The principle applies just as directly to AI systems today.
What production ready actually means
"Production ready" gets mentioned constantly in job descriptions. Here is what it actually means in practice.
Reliability means your system handles unexpected conditions without breaking. What happens when the retriever returns nothing useful? When an API call times out? A production system fails gracefully and recovers.
Observability means you can see what is happening inside your system after deployment. Are you logging inputs, outputs, and quality scores in a way that lets you diagnose problems when they occur?
Cost means your system stays economically viable at scale. How many LLM calls does it make per query? Does that remain reasonable if usage doubles or triples?
Edge cases are the inputs your system handles poorly. Every system has them. The difference between a student project and a production ready system is often just whether those edge cases were found and documented before users encountered them.
You do not need to have solved all of this as a student. No one expects that. But if your README shows you have thought about these dimensions, identified the limitations of your own system, and have a reasoned view on what you would address first, that communicates something important about how you think. It signals that you are ready to operate on a real engineering team.
That kind of thinking is what I have seen make a genuine difference when students move from portfolio to interview to role.
One thing to do this week
Take any project in your portfolio. Add one section to the README called Evaluation and Known Limitations. Answer these three questions:
## Evaluation and Known Limitations
**1. What metrics did you use, and what did the numbers show?**
e.g. "Faithfulness: 0.84 after two iterations. Context Recall: 0.71, identified as the next area to improve."
**2. Where does the system underperform, and under what conditions?**
e.g. "Retrieval degrades on queries shorter than 5 words. Fails gracefully but returns low-confidence responses."
**3. What would you address first to improve it, and why?**
e.g. "Improve Context Recall by experimenting with hybrid retrieval. Currently retriever is keyword-only."The engineers who stand out are not always the ones who built the most projects. They are the ones who can examine a system honestly, articulate where it falls short, and think clearly about how to make it better.
That is the skill worth developing. And it is one you can start demonstrating today.
If you are preparing for an AI role and want feedback on your portfolio, feel free to reach out or leave a comment below. And if you have worked with evaluation frameworks or metrics in your own projects, I would be glad to hear what you found useful.