

MCP Won’t Write Your Functions—But It’ll Make Them Consistent

Someone recently asked me a question about MCP—the Model Context Protocol. They have a large number of tables in a relational database and wanted to know whether MCP requires implementing a corresponding server-side function for each one. After looking into the MCP sample implementation and its Python SDK, the following is my answer to this question.
MCP does not aim to reduce the number of server-side functions a developer needs to write. In other words, MCP does not automatically generate or eliminate the need for manually exposing data or functionality from databases, APIs, or tools that LLMs or AI agents may want to access.
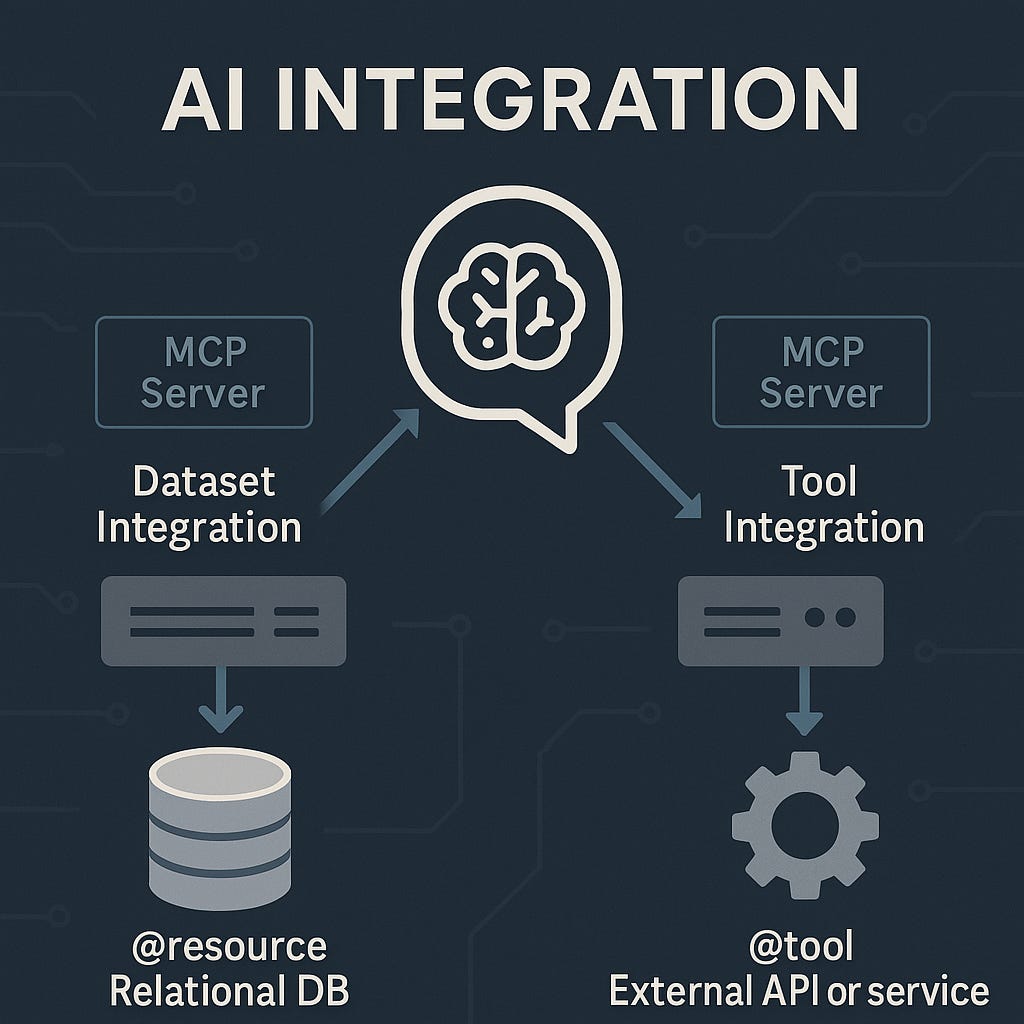
What MCP does provide is a standardized protocol that defines how AI agents and LLMs communicate with external data sources and tools. It requires developers to implement a server-side component for each target system (whether a dataset or a tool) and annotate functions using the MCP specification.
For example, each function that exposes access to data or operations must be annotated as either a @resource (for data access) or a @tool (for actions/functions). This ensures that when developers integrate different systems, they do so in a consistent, interoperable way.
Here's an example of a function that exposes data to LLMs. The @resource annotation indicates to the LLM that this function provides access to data, rather than performing an action.
@mcp.resource("users://{user_id}/profile")
def get_user_profile(user_id: str) -> str:
"""Dynamic user data"""
return f"Profile data for user {user_id}"[Source: MCP Python SDK]
Similarly, annotating a server function with @tool signals to the LLM that the function represents an action or operation, rather than providing data.
@mcp.tool()
def calculate_bmi(weight_kg: float, height_m: float) -> float:
"""Calculate BMI given weight in kg and height in meters"""
return weight_kg / (height_m**2)[Source: MCP Python SDK]
To contrast this with the current approach: today, if you're integrating with five different tools or databases, you typically write five different client-side SDK integrations—each custom, each with different patterns. With MCP, you still write integration logic, but it's moved to a server layer and written in a standardized format. This allows the LLM or AI agent to call any MCP-compliant server in the same way, regardless of the vendor or source system.
The result is a cleaner application or agent layer. The LLM client no longer needs to contain logic like “if accessing GitHub, call this block; if accessing a relational database, call that block.” Instead, everything is exposed through a unified MCP interface, and the AI agent talks to all sources through a common protocol.
So yes, developers still have to write the server-side functions, but they do it in a standardized way, and that integration code is no longer entangled with the LLM’s application logic—it’s cleanly separated into the MCP server component.
Why Separating Access Logic Makes AI Systems More Scalable
One key advantage of decoupling resource access logic from the application layer is reusability. When multiple applications need access to the same set—or even a subset—of data resources, they no longer need to reimplement the access logic. Instead, a shared server-side component can expose those resources through a standardized MCP interface, and any number of client applications can consume them.
For example, imagine you have a server component that exposes five datasets from a database. Thanks to this separation, any other application that needs access to the same datasets can simply reuse or extend the existing server implementation. There's no need to start from scratch. This supports the community-driven principle of building a data access layer once and sharing it broadly across teams or projects.
The same benefit applies to tools, including AI-powered services like LLMs. Suppose your application interacts with an LLM provided by Vendor A, and you later want to switch to an equivalent LLM from Vendor B. As long as both vendors expose their functionality via MCP-compliant @tool functions, you can simply swap out the server-side implementation without changing any code in the application layer. This makes it easy to experiment with different providers or migrate services while keeping your client logic clean and untouched.
I’m still learning about MCP, the spec, and its tooling. If anyone more experienced sees a gap in my understanding, I’d really appreciate any corrections!