

An Intuitive Way to Understand Vector Embeddings
Understanding word embeddings through real-life associations

Embeddings are everywhere in modern AI—from search engines to recommendation systems—but what exactly are they? At a glance, they can seem abstract or overly mathematical. But there’s a simple, intuitive way to think about them, grounded in how we naturally perceive relationships between things in the world. Let’s explore that through a relatable example.
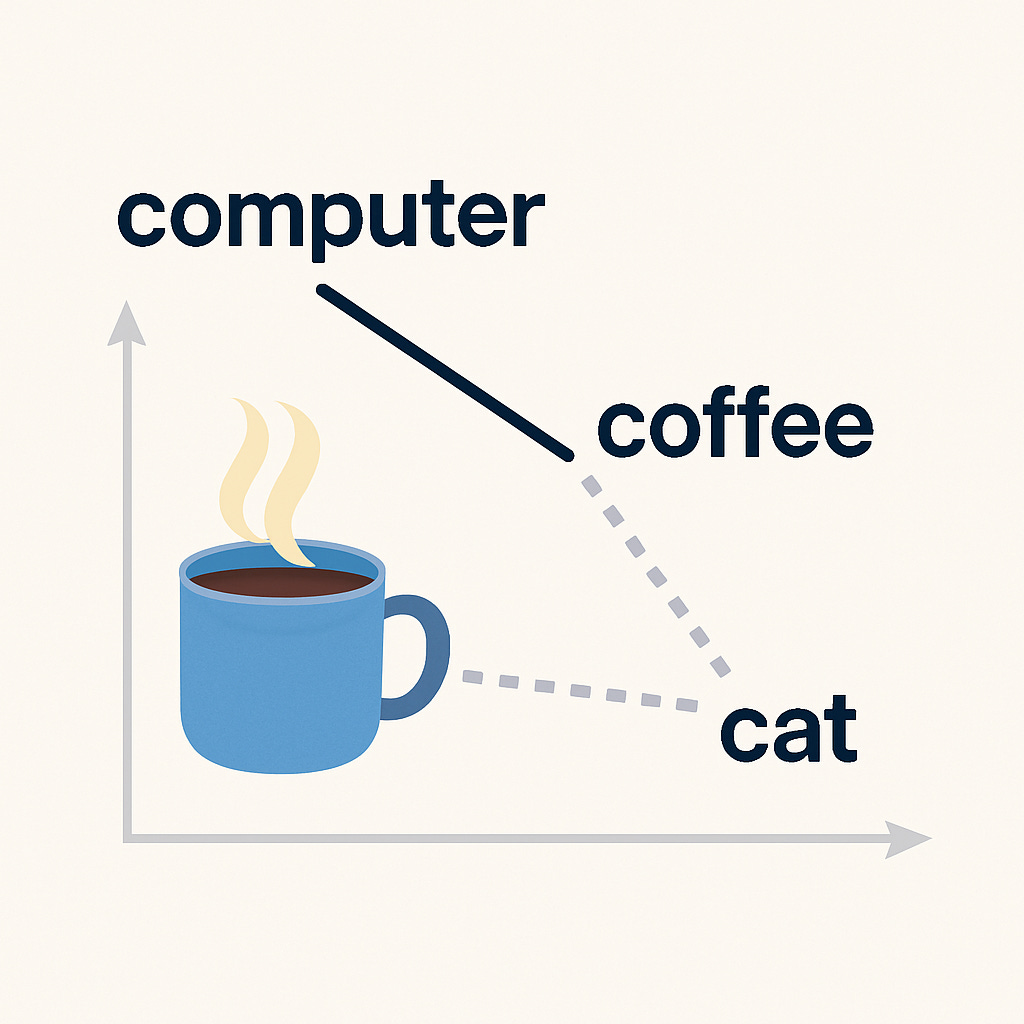
Let’s take three words: computer, coffee, and cat.
Which two do you think are more similar?
Most people would say computer and coffee. Why? Because we often see these two together—people working on a computer while sipping coffee is a familiar scene. On the other hand, cat doesn’t usually show up in that context, unless someone happens to be working with their cat nearby (which happens, but not as frequently).
That sense of association—seeing some words appear more frequently together than others—is the key idea behind embeddings.
An embedding model is trained on massive amounts of real-world text, such as all of Wikipedia. It scans through all this text and observes which words tend to appear together. Using that information, it builds mathematical representations (vectors) for each word. Words that frequently show up in the same context get similar vectors. Words that don’t, like cat and computer, end up farther apart.
Why does this work? Because Wikipedia and similar sources are written by humans and reflect human knowledge and experience. If two concepts are often experienced or discussed together in real life, they’ll often appear close to each other in text—and thus, their embeddings will be close as well.
You can think of it like analyzing LinkedIn networks. If I’m an AI architect, and another person is also in the same field, chances are our professional networks look similar. Our profiles would share common terms, themes, and connections. But someone in a completely different field, say medicine, would have a profile that feels very different. That difference would show up in the embeddings as well.
Embeddings capture this kind of contextual similarity, turning it into a mathematical representation—even when we can’t easily explain the “why” behind it ourselves.
Conclusion
At its core, an embedding is just a way to represent meaning through relationships—how words (or concepts) show up together in the world. It’s not about definitions, but about shared context. And that’s something our brains are already wired to understand. We instinctively know computer and coffee belong together more than computer and cat. Embeddings just give us a way to express that intuition in numbers.